![]() From time to time I get crazy ideas, and last week that crazy ideas was to test how well incremental backups can be restored in the latest version of Plesk. Specifically I wanted to know how Plesk would react in times of a crisis, which usually happens at the worst of times.
From time to time I get crazy ideas, and last week that crazy ideas was to test how well incremental backups can be restored in the latest version of Plesk. Specifically I wanted to know how Plesk would react in times of a crisis, which usually happens at the worst of times.
Up until recently I’ve always done full backups – but incremental backups are a lot more space saving on the target device, plus it reduces the load on the server and data traffic significantly. Let’s see what these incremental backups are all about.
Wikipedia suggests that after a full backup, each increment needs to be available to make a restore. This would indicate that deleting one backup in the middle (simulating a failed backup) would mean the restore would fail.
But how does Plesk work, and how would it react if we’d take away an increment in the middle? Would it indeed need all incremental parts to rebuild a backup? Or would it always refer to the full backup and write its increments accordingly? Let’s find out!
I’m using a test system on a CentOS 7.5 server, with Plesk Onyx 17.8 installed. I have a test domain with a default WordPress instance, but it’s not doing much at the moment and could probably do with a quick facelift if anything.
First Backup
The first backup, after a theme and plugin update, will be the initial version of our site. Naturally it’ll be a full backup. I’ve created a single post saying “Backup 1” for this. It only took a second and went to the server repo, where we shall keep our backups.
Second Backup
I’ve created a second post, adequately called “Backup 2” and created a another backup, this time an incremental one. I’ve also added an image file to see how files are handled.
Third and Forth Backup
Now we’ll make two backup with a new post and another image file added for, followed by yet another incremental backup for each. This will give us 4 posts in total, and 3 incremental backups in total.
Here’s what our setup looks like so far:
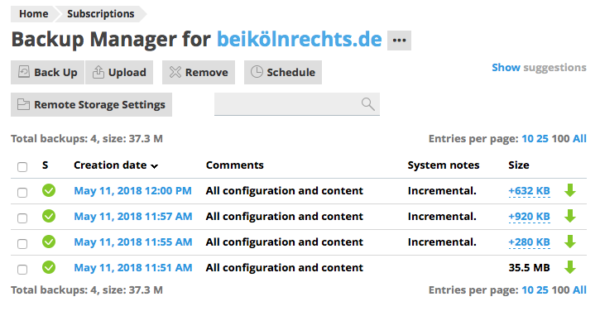
{kind=link}
Full Restore
To make this a super complete test, we’ll start by cleaning out all files and databases from the domain subscription. We’ll do that so that we can check if an initial restore from our initial full backup will actually bring the site back to a state at which we remember it. I’m using the option to restore “all objects (entire system)” by the way.
In doing so I’ve noticed another interesting nugget of information: when deleting a database (and said database is the only one available), Plesk automatically deletes the database user as well. That’s a nice touch, I was going to do that myself.
Having done so, the site comes back with the expected “Apache 123” Testing page.

Our next step is to restore the first (full) backup we’ve made. The result was indeed as expected: no error messages are displayed in Plesk, and the domain (including my login-nonce) was brought back to life, right after I had created my first post.
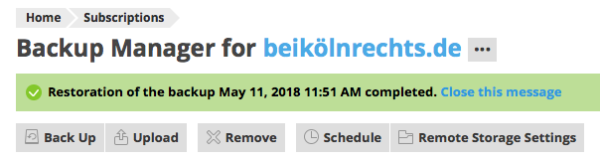
Incremental Restore
Now let’s do the same as before, but restoring our last backup. This would mean Plesk has to read the first (full) backup, as well as each incremental backup. Again we’ll remove all files and databases to make this a complete test.
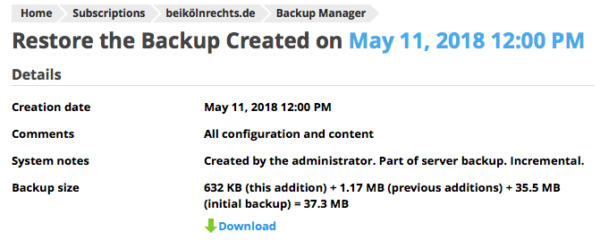
When we click on the latest of our incremental backups, Plesk does indeed add up all previous additions (1.17MB in our example) and acknowledges that the full backup as well as all incremental parts are needed. Good to remember.
The restore worked perfectly, and all images and posts were brought back to life. Result!
Simulating Trouble (Part 1)
Let’s assume that in a real-life situation, our second incremental backup would have failed. The big question then becomes: will Plesk be able to restore what we have, or tell us that it can’t deal with the backup at all? It’s an important thing to consider because it will have an impact of how many incremental backups we can “risk” before the whole series becomes corrupt.
To simulate this, let’s delete the second incremental backup from the server repo (perhaps downloading it beforehand, just to be on the safe side). Next we’ll remove all files and databases again, before restoring the final backup in the series.
Another interesting observation: when I’ve tried to download the second incremental backup (in our example 920KB in size), Plesk proceeded to download the whole 38MB as a single file. It has obviously re-assembled the whole incremental series so that we’re left with a single file. How nice is that? I had no idea it would do that. See, this is why testing such an endeavour in our own time is so important.
When I tried to remove the incremental part if our backup series, Plesk does acknowledge that this is going to git rid of the whole backup. Very interesting!
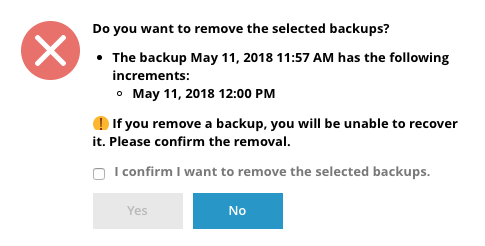
What happens if I say “yes”? Let’s find out!
Turns out Plesk removes the file I’ve selected, plus all following increments. It will leave the initial full backup and the first increment in peace. That makes sense: it will still let us restore the second backup, as it only relies on the full backup and the first increment.
I have also tested to remove the last part of the incremental series in another test, and the above dialogue box does not show up. There’s no need for it, since it is assumed that we’re simply removing the last entry in our backup series. Use thought I’d mention it in the spirit of thorough testing.
Simulating Trouble (Part 2)
Let’s take this one step further: since I can’t simulate a missing increment in the series via the web interface, perhaps I can simply delete said file via the command line. Let’s see how Plesk handles this.
I’ll re-create my series as I did above (one full backup, plus three increments). Because backup files stored on the server (in /var/lib/psa/dumps) are a bit of a mystery to me, as they are made up of a combination of tar and xml files, I’ll make my backups to an FTP repository. This will create single tar files so I know which ones to delete manually.
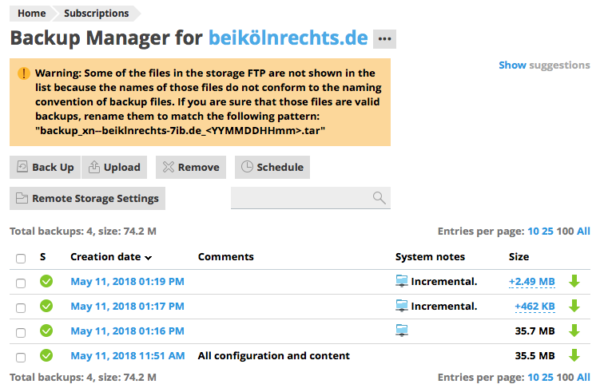
As above, I’ve deleted the second incremental backup file from the FTP server.
And once again, Plesk is on the ball: when I refresh the page, it notices that something fishy is going on here:
Let’s see what happens when we try to restore the final backup in the series. How will Plesk react? Will we be able to it at all, or will it try to do a partial restore? Once again I’m clearing all files and databases before I proceed.
Plesk gives us a pretty good idea of what to expect:
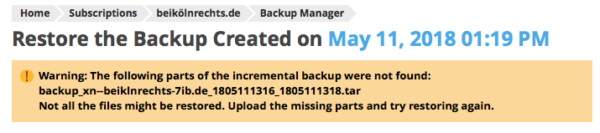
In reality however, the restore task seems to hang: Plesk starts by copying all relevant files from the FTP repo over to the server, so we’ll see two copies of our backup increments when we refresh the page. We’ll also see the familiar progress icon spinning at the top of the page, but no matter how long we wait, Plesk can’t seem to restore any of our files 
The hung task can be stopped using the convenient “stop” option next to it. Should this not work, there are several KB articles that explain how to kill these tasks from the command line
- https://support.plesk.com/hc/en-us/articles/115004852554-How-to-stop-the-hung-backup-or-backup-restoration-task-
- https://support.plesk.com/hc/en-us/articles/360001380633-Backup-restore-task-hung-in-Backup-manager
- https://support.plesk.com/hc/en-us/articles/115002120793-How-to-delete-a-stuck-task-
What happens if…
Another question that was bugging me was this:
Say you had uploaded a file after making a backup, and then you restore that backup. What happens to the file you’ve uploaded afterwards? Or what happens to a database entry? Will Plesk remove all files and database entries before restoring a backup, or will it “add” the files and database entries to what’s already there?
Let’s find out with another quick test!
Turns out that for files, it does pretty much what I would expect: Plesk leaves everything that’s currently stored in the subscription intact and will copy files from the backup over what’s already in place. So if a file exists in the backup it will be overwritten, while files already in place that are not part of the backup will be left alone. Good to know.
Database entries on the other hand are dropped before being restored, and hence completely overwritten with whatever is in the backup. Also good to know.
For WordPress this means that as a result of the above behaviour, the actual files may still reside in wp-content/uploads, however WordPress won’t be able to show them because the database entry linking to said files no longer exists.
Conclusion
While I like the idea of incremental backups, there is a slight security tradeoff that we need to be aware of. Say we made a full daily backup, and for whatever reason one in the series fails, all other backups can be restored without problems.
However, if we encountered the same trouble with incremental backups, a successful restore really depends on how long ago the last full backup was made. If we’re choosing to do full backups once a month, we run the risk that nearly a whole month of data might be lost. While very space and load saving, running only one full backup a month appears to be risky.
I guess a good compromise then is a weekly full backup with daily increments. It’s a good tradeoff between not ever losing more than 6 days worth of data while keeping space consumption on the target device to a minimum.
But the most secure strategy would be to stay away from incremental backups altogether and instead stick with full daily backups – if your infrastructure can handle it.